Howdy! I'm Kevin Zhang.

I am a
Computer Scientist.
Roboticist.
Research Engineer.
Machine Learning Expert.
Amateur Chef.
Cat Person.
Mega Tennis Player.
About Me
I am a Software Engineer at the Toyota Research Institute, working on the Planning and Controls - Prediction team for autonomous vehicle development. I graduated from Olin College of Engineering with a Bachelor's degree in Computational Robotics Engineering with a concentration in Computer Science. It's a modernized major that combines the technology and expanding topics in robotics with the fundamentals and implementation skills of computer science. I am deeply passionate about both software and robots, and as a most curious cat, I just couldn't say no to either one! An avid proponent of the balanced work/life philosophy, I strive for challenges and endeavor to learn from and contribute to technological progress, but also pause sometimes to enjoy the small things in life.
"Kevin ... worked on a system for helping with internal testing, interfacing with various sets of hardware and writing algorithms based on data received from said hardware. He jumped right into the challenge, learning the project background quickly, and contributed significantly to the success of the project ... The work resulted in a technology concept which will add to the patent portfolio at Ivani. Kevin’s natural intelligence and commitment to the company were evident throughout the summer. He naturally adapted to our culture, while impacting it in a positive way. Having Kevin work with us for the summer was awesome, and I would not hesitate in recommending him to future employers."
- Matthew Wootton, Chief Technology Officer at Ivani LLC
In academia, I held a 3.90 GPA and led the Olin Interactive Robotics team. I actively do a lot of self-learning in the fields of artificial intelligence and mobile robotics, in particular machine learning and human-robot interactions. In my private life, I regularly indoor rock climb, play tennis and perform strength training to maintain a healthy, well-rounded lifestyle. I also have fun pursuing various adventures such as multi-pitch outdoor rock climbing or goat yoga. I enjoy learning new things, hanging out with friends, and exploring new places. A relentless pursuer of all three prongs of the urban legend's academic triangle of Sleep, Social Life, and Success, people back at home know me as "The Zhangster", famous for his booming and bright laughter, and the guy you can always depend on.
Want learn more about me? Click below.
More About MeHighlighted Experience

Toyota Research Institute
2019-Present

amazon robotics
2018-2019
nuTonomy
2017

Ivani
2016

Highlighted Projects

Project: Gemini
Robotics Systems and Integration

Project: Nevo
Computational Mobile Robotics

Frost
Stark Industries
Want to see more of my portfolio? Click below.
Full PortfolioToyota Research Institute
Software Engineer
2019-Present

The latest vehicle used for autonomous development at TRI.
Toyota Research Institute, the research arm of Toyota, performs cutting edge research on robotics with the ultimate goal of advancing technology to improve safety, mobility, and human ability. There are several divisions in TRI, such as household robotics, advanced battery design, and autonomous vehicles. The autonomous vehicles division was researching a two-step path to product towards automating vehicles, first with Guardian, a partially intelligent vehicle that can aid the driver in dangerous and inconvenient situations, and then Chauffeur, a fully autonomous vehicle that can completely drive on its own. In August of 2019, I joined Toyota Research Institute as a Software Engineer on their Automated Driving division. Autonomous vehicles was exactly what I wanted to get into after college, and with TRI I had the opportunity to do exactly that, so I was very excited. I started Day 1 with 110%, ready to learn a ton about robotics in industry and also contribute a ton to the success of TRI's Guardian vision.
About three months after starting, I was well past onboarding and deep into working on tasks and projects. A major complaint I kept hearing from my teammates was how long and tedious it was to iterate on technology development. Procuring data logs took an incredibly long time to download from the cloud, gathering a dataset was even harder and longer, and testing features was practically limited due to the data storage system's lack of capabilities and flexibility. There didn't seem any movements or efforts to make things better, so I decided to make one. Starting from gathering user stories to defining my own requirements to designing and implementing a system to user testing and iteration to finally deployment, near the end of 2019, I went above and beyond to create FAST, a brand new system built from scratch that automated and substantially sped up TRI's data storage system. FAST revolutionized data storage at TRI, reducing download times from hours to seconds, provided automated dataset curation capabilities with the click of a button, and made testing significantly easier, opening the floor for new testing systems to be developed. Feedback was overwhelmingly positive, and a month later I worked with others to fully integrate FAST into the TRI organization workflow. FAST became the atomic unit of data at TRI, and still is to this day. Even after FAST's hype plateaued and it settled into the normal everyday flow of everyone's work, later systems and newer architectures continued to make use of its flexibility and build off of it to create new testing components, new machine learning pipelines, etc. And it's worth noting that my manager did not assign this to me as a task. There was no top-down effort or anyone telling me that I need to do this work. FAST happened because I saw a problem that I had an opportunity to solve, and I intrinsically wanted to fix it and make things better.
At around the same time, I had pushed a number of changes and new code into the organization's code base. At some point I started really wondering whether I was impacting the stack's computational performance, whether it was getting too slow. I asked around about timing and budgets for the planning and control stack, and was surprised to hear that while there was some word-of-mouth understanding and communication of how long our stack took to run or how long our stack was supposed to run, there was no agreed upon timing contract. So I talked with my team and created an initiative to concretely agree on a timing contract between all major teams in the driving division. I led the effort and engaged heavily in inter-team communication, organizing meetings to discuss budgets, and co-creating a website that processed the latest timing numbers and made computation performance easily accessible. Ultimately, near the end of Q1 2020, we were able to establish an organization-wide timing budget, we had deployed a website to help track the timing budget, and most importantly, we had helped push the conversation of timing and performance into the spotlight. Through my work, the organization actually realized that its major components in the stack were going over allowed timing budgets unnoticed. Teams started paying more attention to performance, and across the board the stack was able to start driving its timing performance down significantly to acceptable budget standards. Today, the numbers in the contract have changed slightly, but the budget is still very relevant and teams still use it conceptually to discuss performance and keep an eye on the stack's computation limits.
By this point I think I had proven myself to the company to be a valuable teammate, as my manager soon came over and handed me a very broad and high level project whose mandate was to create a new self-contained component to localize surrounding agents to lanes on the road. There was some functionality that existed already, but it was primitive and not modular enough for longer term usage. Thus the goal was to create a new and improved system that could stand the test of time. I worked with teammates and led the project to design a new lane association system. The outputs of this system would be critical to the prediction team's stack, as it would basically decide how the stack would handle incoming obstacle inputs. It was a great responsibility, and I took it on in stride. After about 3 months near mid-year 2020, we had deployed a robust model-based system that could consistently deliver accurate associations for any obstacle in the road. The prediction stack was working much smoother, and with more consistency given the new inputs from the lane association system. In addition, the system was built flexible and modular enough such that once others saw it working in deployment, they also wanted to use it and augment its capabilities. Today, the lane association system is now more of a spatial inference system, as it serves multiple use cases and contains a multitude of related functionalities beyond just lane association. Several outputs are used by other teams in addition to even different components within just the prediction stack. This was the first major project I took from conception to implementation to deployment that had direct impact on the stack itself, and along with my work on machine learning projects explained below, my performance on leading these projects and getting stuff done was strong enough to receive a promotion within 2 years of starting at TRI.
After deploying the lane association system, I was given another high level project to add a new feature to the prediction stack, which was enabling cross yielding prediction support. The mandate was to give the prediction stack the capability to predict which vehicle was going to go first at a crossing interaction, e.g. unprotected left turn scenarios. I led this project, and once again started with defining user stories, creating scenarios, and defining requirements for the MVP. I then worked with some teammates to design a model-based system to predict crossing interactions. I implemented the design and tested it using datasets curated from FAST. Near the end of Q3 2020, I deployed a crossing yielding system MVP that can handle crossing interactions between two vehicles. My system was the first in the stack to attempt to conquer the crossing interaction scenario, and the work I put into the system paved the way for the eventual handling of crossing interactions by the entire stack such that the subject vehicle could actually behave and move appropriately in reaction to what it thinks other vehicles are planning to do at the crossing interaction.
At around the same time as working on the crossing yielding project, I was also personally very interested in machine learning, and I noticed some other machine learning projects happening within the team. I reached out and asked them what they were working on and if there was anything I could work on to help and get involved. I was able to get on a project involving a deployed machine learning model in the prediction stack. A teammate wanted me to help expand a RNN model's operation domain as well as improve its accuracy. The model name's is the Corridor Intent model, and it basically predicted what lane a vehicle was going to drive in over the next few seconds. The problem was that it was limited in the scope of vehicles it can work on, and it performed poorly for certain edge case scenarios. Intrinsically motivated to dive in, throughout the second half of 2020, I put in a lot of time to experiment with the model and dive into the data or change aspects of the model to see what happens or watch how the model reacts to different scenarios. I then upgraded the dataset used to train the model as well as performed exhaustive evaluation to deploy an upgraded model that would work in more scenarios beyond the original to the same bar of quality. In addition, a separate effort that I worked on also for Corridor Intent was to explore adding in new features to improve the accuracy of the RNN model in specific pain point use cases, primarily cut-ins on the subject vehicle's lane. I performed novel research to experiment and understand the effect of different features on the model. I also experimented with some different techniques to change data representation which might make it easier for the model to learn from. I then made an empirical argument for what I thought would work the best, convinced my teammates that this was the best way to go, and then implemented and deployed another upgraded version of the model that could handle cut-ins more accurately and in a faster horizon. Evaluation systems for the prediction stacks were telling me that the work I had done for the Corridor Intent system improved its accuracy overall by about 19%. I learned a lot about data and learned modeling techniques and how they're used in deployment and industry. My work on the Corridor Intent model also helped drive down critical bugs and meet OKRs for the driving division as a whole.
Having worked on some machine learning projects at this point, I felt strongly that we needed to dive deeper into learned models in the prediction stack. Talking with other teammates and putting together a comprehensive strategic document for why we should move more into machine learning, I convinced and helped my manager come up with a concrete plan to work on long term machine learning projects. Specifically, we devised an initiative to develop a machine learning pipeline for the prediction team. I wanted to design a long term machine learning workflow that could be robust and flexible for a multitude of learned models and use cases, such that we could identify and deploy multiple models using this single pipeline. The grand vision we came up with was that we could eventually turn the entire prediction stack into a purely data-driven stack, and all of the models that made it up were supported by a single, powerful, adaptable pipeline called PLOP, which did everything from data curation to dataset generation to model training to deployment to evaluation and back to getting more data and trying training again, an endless iterative cycle. It was a huge project and there were numerous pieces, but to speak at a high level, I was in charge of the data curation and model training components of the pipeline. It was a grand embarking that we took from conception to design to implementation over the course of 6+ months. By early 2021, we had completed the data pipeline and were training our first learned model use case, learned pedestrian prediction to predict where pedestrians would walk around in general. Near the end of Q1 2021, we had deployed an MVP of the first use case of PLOP to predict pedestrians. The deployed model showed promise and was on a strong trajectory to become the main predictor for pedestrians in the stack. My work on data curation and model training actually scaled to hit the maximum limit of the organization's cloud team's infrastructure, so ultimately we had to scale back our scope. But to date this was definitely the peak of my performance and of the team's performance, where we learned the most and contributed to something that had the most impact for the company. Although at the end we hit the limit of our company's resources at the moment, I think we still set up a robust, long term pipeline that can be used by future learned models for machine learning development, generalized enough even to be used by other teams in planning and controls. We did great work that set up the proper fundamentals for future development, and I personally learned the most so far at TRI working on this project.
Now presently starting from Q2 2021, I am moving more into a Guardian-specific project. I was given full ownership of the Ego Intent project, a cutting-edge intiative whose mandate is to predict what the subject vehicle's driver is intending to do up to 3-5 seconds in the future. The project has huge potential for TRI and TMC, the parent company to TRI (Toyota Motor Corporation). If deployed into commercialization, there is direct path to integration with existing Advanced Driver Assistance Systems within Toyota vehicles as a standalone system that could substantially improve upon current L2-3 autonomous systems in current Toyota vehicles driven by private owners. In addition, the Ego Intent system would serve as the critical input into the Guardian System to provide comprehensive understanding for driver feedback into the system, acting as the closed loop mechanism for the Guardian stack. I had a very small team to spearhead development on this project, and even then I progressed quickly. I personally self-designed the entire system from start to finish in less than 3 months, with some feedback from teammates for sanity check and outside input through design documents and organizing meetings. As of October 2021, I have a full final design for an MVP of the Ego Intent component architecture and implementation details, and am getting ready to dive into building it out for the initial pipe flush. The Ego Intent project is taking a learned approach to solve the problem, and so there was opportunity to borrow aspects of PLOP, the pipeline I helped make previously, specifically the data curation and deployment components. However, the Ego Intent system is fundamentally different from other prediction work I've done because it focuses on the subject driver instead of surrounding obstacle drivers, thus I created a full design by myself for the rest of the machine learning pipeline, including dataset generation, data validation and loading, model training, and the model itself, which was a new RNN model. Not only did I own the project, but I also took on leadership responsibilities to manage the project, coordinating and collaborating with the other teams in the Guardian effort, and delegating tasks to teammates working on the project with me. I am taking on greater and greater roles here at TRI, leaning more into leadership both team-wise and technical-wise. I hope to move further into this direction, as I think that I have an intrinsic knack and personal passion for it. Moving forward, I hope to implement the first version of Ego Intent for deployment by the end of Q1 2022. I also hope to take on more and more responsibilities and own more and do more for the team, both from a people perspective but also a technical expertise perspective.
And that's it for now! I'm still working at TRI to this day, and this page was updated as of October 31, 2021. I hope to update this page in the future with even more endeavors and cool accomplishments. One thing I want to mention here is beyond all the projects and work that I'm loving doing here, I'm also very grateful for my team and the people and culture that I get to work with. I truly believe after working at TRI that it's the people that make or break a project or a company, and so I'm very happy to be working with some incredibly smart and incredibly kind coworkers and friends. They've taught me a lot and heavily trusted me to deliver. I've made some great friends here who I will definitely continue to stay friends with even after I leave TRI someday, and I really appreciate everything they've given me over these past few years.
amazon robotics
Software Development Co-op Collaboration
2018-2019
Amazon Robotics, a wholly owned subsidiary of Amazon.com, empowers a smarter, faster, more consistent customer experience through automation. Amazon Robotics automates fulfillment center operations using various methods of robotic technology including autonomous mobile robots, computer vision, depth sensing, and machine learning. For my final internship in undergraduate, I embarked on a 1+ year long co-op collaboration with Amazon and Olin that would solidify and conclude my project-based learning experience. I interned at Amazon Robotics with a team of 4 others, and we were tasked to help research and develop a robotics system that would enable the company to completely automate their warehouses, from when items come in to when packages are sent out for shipping. Our project was to come up with new, innovate solutions to approaching automation and e-commerce, and to show the feasibility our ideas with a fully-built prototype to be demonstrated to Amazon executives. After about 10 months into the project, we had accomplished just that.
Our project was highly open-ended, as the main criteria was simply to help Amazon come up with a system that could help them achieve their goal of end-to-end automation in a warehouse. I was the only software engineer on a team of mainly mechanical engineers, so it was my job to cover everything that wasn’t hardware-oriented. We engaged in various forms of brainstorming and research at first, and we came up with the general idea that there will be some sort of storage system involved, and individual mobile robots will move between these storage units to handle and process item orders. The question was then which approach to the storage system and the robot would lead to the most optimal increase in productivity and scalability for Amazon. We began narrowing down to a few ideas and modeling them in real life using cardboard and wood. I ,being in charge of the entire software system, also began building out a preliminary architecture that would enable autonomy within the overall system. Through iteration and team discussions we made a plan to fully build out one of our ideas to showcase to Amazon at the project’s Midpoint Presentation. I not only finished building the software stack for the mobile robots and the storage system, but I also moved down to firmware and helped get a lot of the low-level sensor reading and processing working too. I also helped integrate with the mechanical system with teammate Cedric Kim, which was a huge effort due to a team miscommunication prior to integration. By the Midpoint Presentation, we were able to successfully demonstrate a working prototype of the idea we found most promising. It wasn’t perfect, but it was a start in the right direction.
Moving into the second half of the project’s timeline, we realized that our original promising idea was flawed in various ways, so we moved to further crystallize and concretely define exactly what the best system would look like. At this point, team communication was showing signs of stress and wear, and team members were having difficulty fully narrowing down the optimal design within our parameter space. I began also taking on a project manager’s role to help facilitate healthier and more productive team meetings so that we could quickly pin down the best design and scope out how we would go about building a prototype for it. As a result of my efforts, other team members’ engagement were reignited, and we swiftly made progress towards the optimal system. The new system required a significant redesign from our previous model, as it was a heavily improved version of the first. The mechanical team got to work, and through the length of the second half, I redesigned the entire software architecture twice until we managed to iterate to a promising implementation of our system design. I also helped redesign the firmware for the robot as well, and once again co-lead integration with my teammate Cedric. I continued to take on a leadership role in managing the project to ensure that all components of the system were finished on time and adequately synchronized in their dependencies. I also ensured team health was doing well, and assisted team members with problem solving and bandwidth distribution. Towards the end of the project, we had a much smoother integration and testing phase between components compared to the first half, and we once again had a successful demonstration of our final system design to Amazon.
Amazon was extremely pleased and intrigued by our work. We were able showcase a fully autonomous robot capable of interacting with a novel storage system design to fetch and stow items on demand. They plan on patenting our final system design, and we received very positive reactions from Amazon executives all the way up to the COO of Amazon Robotics. Personally, I have learned a great deal of how projects might work in the real world, and I also have gained more experience in working with sometimes difficult teaming situations, as well as project leadership and navigating through those rough times. I consider this my greatest and final learning experience as a college student, and I thank Amazon and my team for everything they have taught me. I will continue to dive deep into the world of mobile robotics, adaptive learning models, and artificial intelligence (perhaps even in the cloud!), and am planning on searching for a full time position in a computational robotics role.
nuTonomy
Autonomous Vehicle Intern
Summer 2017

(Above) A team picture of the crew. (Bottom three) snapshots of an MVP of nuZebra.
nuTonomy is a fast-paced startup with a bold mission of completely changing the urban transportation scene. They aim to create their own fully functioning system that enables perception, localization, mapping, planning, controls, and safety for an autonomous vehicle. And their software, nuCore, is on track to make it a reality. As one of the only two undergraduate interns given the opportunity to work with nuTonomy over the summer, I dived right into the fray to not only learn more about the world of driverless cars but also contribute to the company and help them reach their goal.
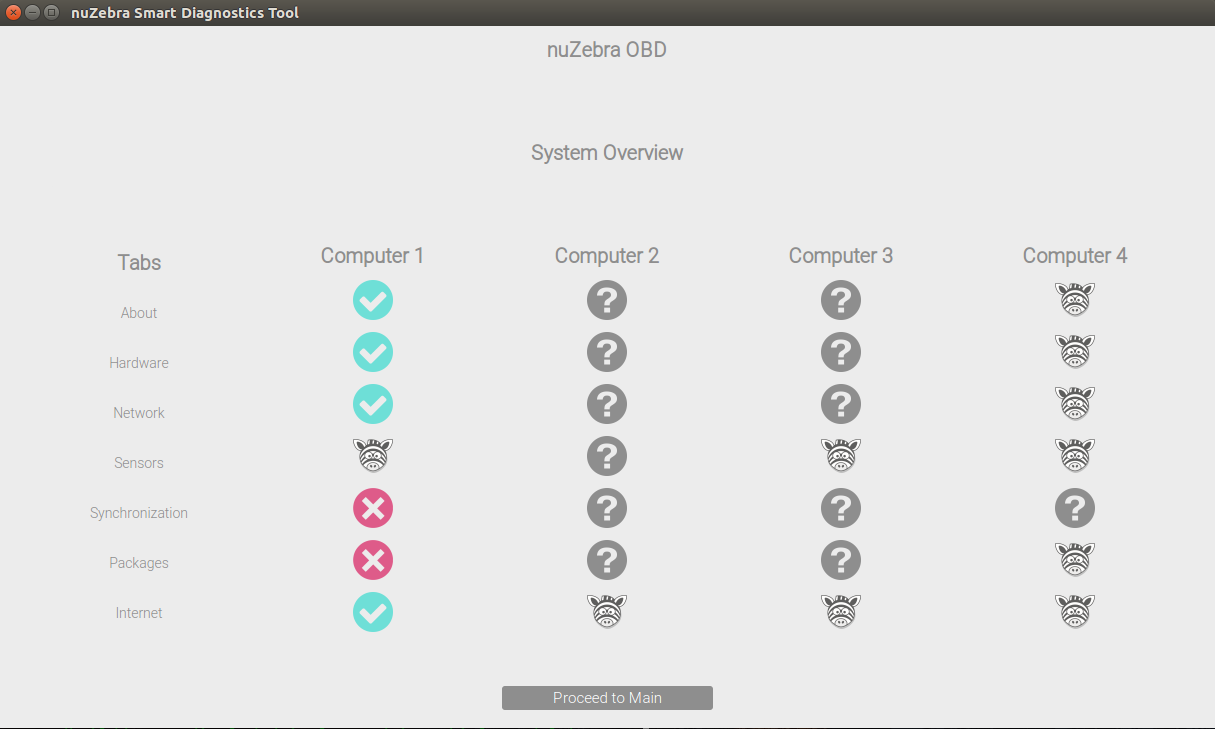
At the start of the internship, I was tasked with the formal project of creating a smart diagnostics tool for Team Car, the group that interfaced most closely with the autonomous cars themselves. I was to work alone on the project, and the only major requirements were that it could scan as many aspects of the car as possible and provide immediate feedback as to the car's condition, and that it remain easily usable, maintainable, and modifiable, as future users might find a new problem that they would want added. Doing my own research, I realized that Team Car was largely responsible for software road release testing, car maintenance and conversions, as well as code debugging and software release management. Whenever a problem was discovered, such as a car breaking down or the code not working, Team Car would have to go down a large list of possible problems and manually check them one by one. Observing them one time attempting to figure out why a car wouldn't start, I found that it could take them up to a week just to resolve an issue before even starting with testing or more productive items, and often times the same type problem would occur, making it seem like the team was running in circles. The goal for my tool was to automate this process, and prevent unnecessary manual labor from hindering progress on the software new releases. Thus I began to work on the tool, later naming it nuZebra (zebra is slang for "exotic diagnosis" in medical circles).
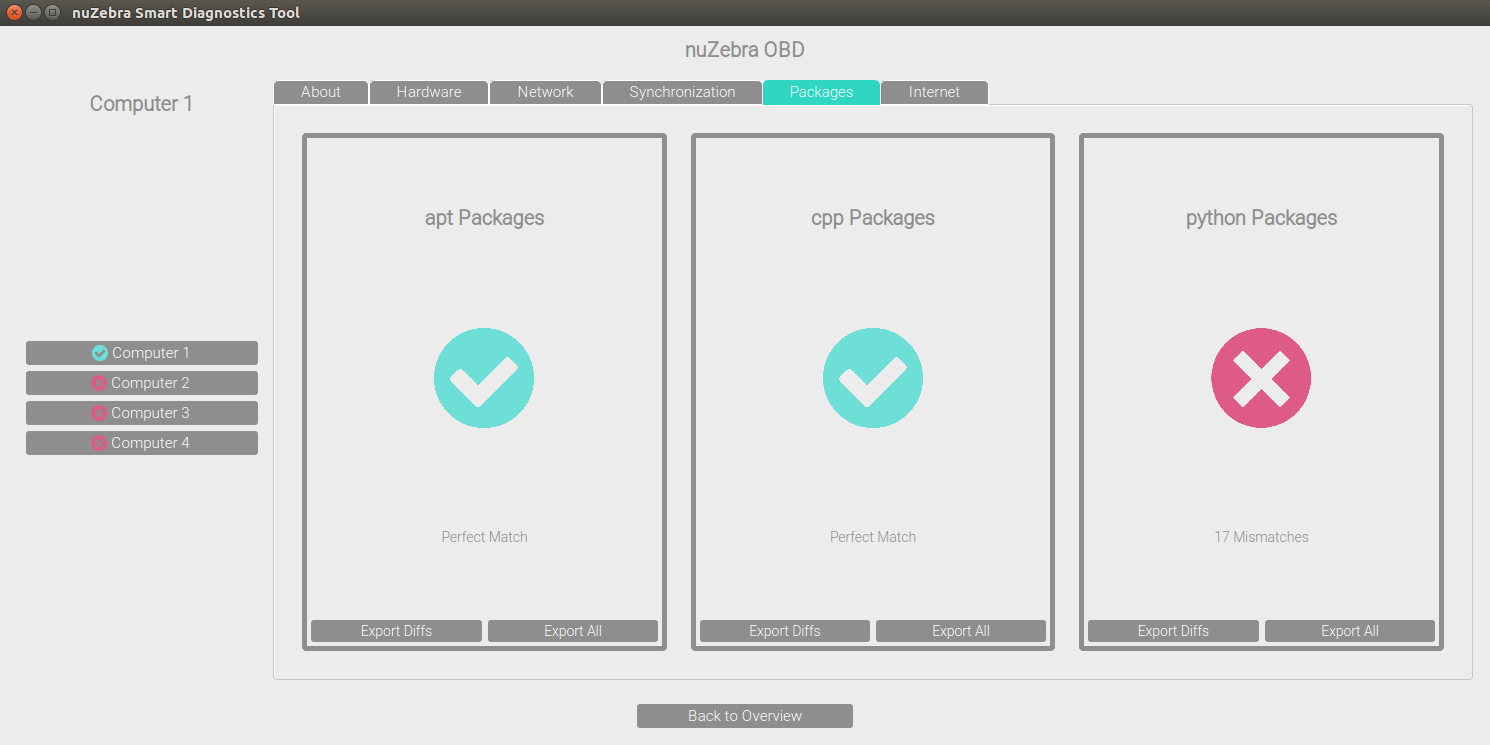
To begin, the tool needed to be scalable, yet fast and accurate. Since a number of people in the company weren't software majors, the tool also needed to be easily usable by a lay man. I used Python and PyQt as my main interfaces because the company was most familiar with these libraries across the various teams. I decided to build the tool from the ground up and use an iterative process to prototype increasingly complex interfaces and frameworks, taking into account feedback from others. I spent most of my first six weeks creating the backend framework, making sure to establish a modular, multi-layered code architecture, such that later code modifications were easy and did not disrupt the core of the software. After finishing the backend mechanism and ensuring proper functionality of the tool, I turned to content creation and front end design. Since the software I was creating was meant to be an internal tool used by the company itself, I decided to hold weekly meetings with company members to get their input on how the tool looked and felt. Near the end of the summer I also held a Team Car-wide meeting to get their feedback on the UI, since they were most likely to be the main users. I ended up designing a highly minimalistic interface with nuTonomy's color scheme and simplistic buttons as the main interactive mechanism. All data and information was split into high level and lower level types, with high level immediately displayed and lower level accessible with the push of a button. The tool covered software statuses and release versions, sensor statuses and incoming data, as well as system information and hardware data. There was also room for car CAN bus data as well as mechanical outputs, but due to time constraints I could only create the framework for those. After many iterations and much polishing, I was able to deliver a fully functional, well designed nuZebra to Team Car.
In addition to its completion, I was also able to deploy my tool onto the cars. We tested nuZebra on the autonomous cars to great success, and even went out on a software road release after using it to efficiently ascertain the status of the car. The team was glad that they could now spend less nights working at the company, and my manager was even surprised by the ease of use and amount of data I was able to incorporate into nuZebra. They plan to use it for future testing and incorporate it into their formal car startup and road release sequences.
(Left to Right) Visualizations showing the proof of concept of the Reinforcement Learning environment being implemented on a parked car avoidance scenario, first starting out, then training 1500 trials, and then converged behavior after 1500 trials.
My main project was going so well, that at some point I realized I was almost a month ahead of schedule. With my manager's approval, I decided to seek out new side projects where I could help other teams on as well, since I had the extra time and desire to learn about what other teams were doing.
I found a side project with the perception team, who was looking for a way to automate config/param loading and execution. At the time, for every different scenario or car, the team had to write up a brand new config file, manually download the data logs and then hardcode numerous environment artifacts so that they could load it into the system upon runtime. This resulted not only in slow testing iteration, but also created a troublesome 100GB+ structure in the codebase due to massive numbers of config files that had to be saved and data logs being held on disk, most of them being identical save a few differences for different maps or scenarios. I then helped the perception team design a generator that could automatically create config files in real time and handle data from the cloud. It utilized a pool of possible config templates, and then with a few parameters could build a new config file for that specific run of the system. Using the information from the auto-generated config, it could download the appropriate data logs and environment artifacts on demand instead of holding them all on disk. The generator was also wrapped up as a nice executable module, so all one had to do was call it and it would run with the given parameters. The generator was also built to be highly modular, so the parameter/config file could be customized as much or as little as one wanted. The generator ended up cleaning up a huge section of the codebase, and since it could be called at runtime, streamlined execution of the nuCore system.
Due to the first one going so smoothly, I also found a second side project to work on. The planning team head was curious about potentially incorporating new models into the planner that determined how the autonomous car moves, and he wanted someone to spend time exploring different types of planning models. The planning team head noted he believed that there is a fair chance the optimal planner would require both deterministic and nondeterministic models to fully account for all possibilities. Since the current model is mostly deterministic and operates on a priority-rule based system, he wanted me to research nondeterministic models and their feasibility in solving complex problems. After much digging, I learned about multiple different options, such as Sequential Game Theory, Value Iteration, and Learned based models. I became very interested in Reinforcement Learning as a potential candidate. Since it was the backbone of AI achievements such as conquering Go, Chess, and most recently a multiplayer online video game known as Dota 2, I thought it might work as a suitable model. I did a lot of offline self-learning and research in an effort to fully understand Reinforcement Learning and how it might work in mobile robotics planning. Towards the end of my internship, I was able to construct a Reinforcement Learning environment that solved mobile robotics problems. I then applied it to a parked car scenario and created an MVP, which I presented to the planning team lead. Due to time constraints, I used a fairly simplistic Reinforcement Learning implementation, where I built a Q-Learning machine learning algorithm. The position of the vehicle was considered the state space, and the actions in this instance were discretized to be turn left, turn right, go straight, or stop. I then used an advanced form of the Bellman equation with a simulator that I built to simulate a converged behavior of the autonomous vehicle successfully navigating its way through the scenario. The MVP showed that RL-based models could be feasible for autonomous car planning, albeit some caveats and further research needed to more concretely ascertain its exact usefulness. The planning team was grateful for my efforts in exploring an unknown territory for them, and said they plan on looking into it with more scrutiny in the future.
My experience with nuTonomy was an amazing and symbiotic one. An autonomous vehicle company like nuTonomy was my dream company for this summer, and I got my wish granted. I worked harder than I ever had before for a company, and helped them optimize their codebase, improve their testing and car system, as well as introduce new potential models to the planning team. In turn, they gave me so much advice and taught me many things about mobile robotics, planning, and AI systems. Most importantly, they helped me finalize my decision to pursue mobile robotics as my career path. Moving forward, I hope to immerse myself further into the world of robotics and intern at a larger robotics company to gain even more experience. I look forward to the day I can see a nuTonomy taxi on the roads in Boston.
Ivani
Software Engineering Intern
Summer 2016
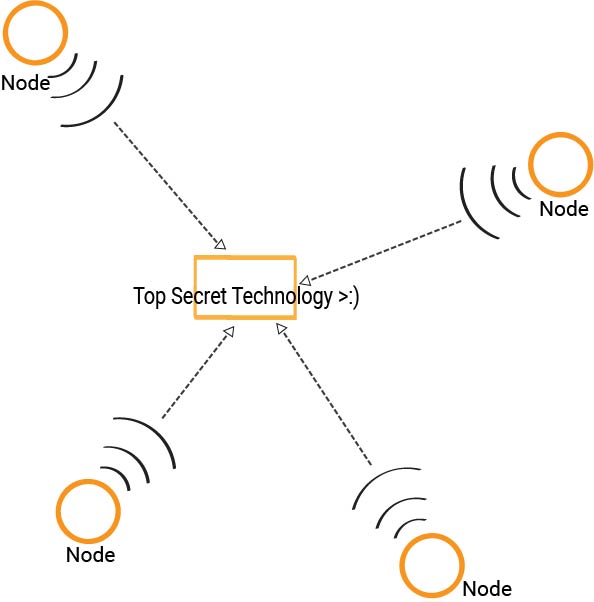
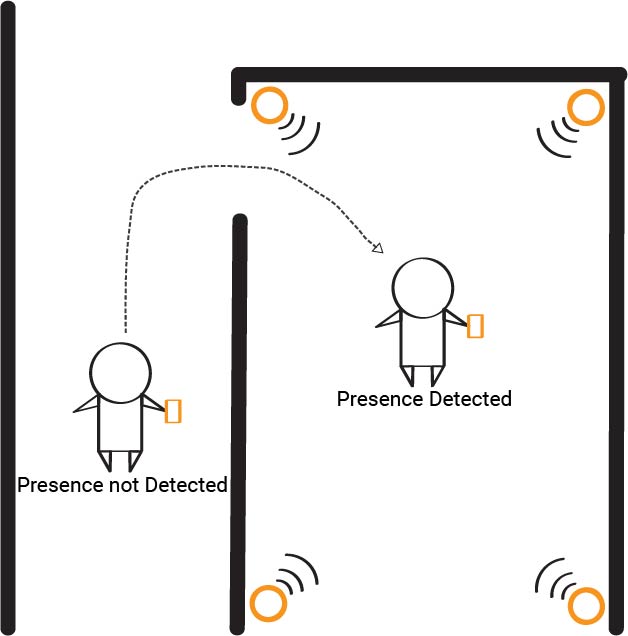
A basic visual of the technology my team created
Ivani is a start up working on revolutionary network presence sensing technology that allows wireless communication systems to observe RF disturbances without the addition of new hardware. It then analyzes these disturbances to determine the physical occupancy of a person inside a room. As a college freshman, Ivani took a chance on me as a student with comparatively less experience but equipped with a wide array of skills and a bright motivation to learn and make an impact, and I seized the opportunity to deliver.
Teamed up with fellow Oliner Liani Lye, I was assigned the task of creating a testing module for the company's original presence sensing system, with the idea being to train the original. We exceeded the project goals and ended up developing a brand new patent-pending presence sensing technology that not only trained the original system but could also act as a stand alone presence detection system. The technology we created both detects a person's physical presence, and also determines where the person is in reference to the detection field, such as how far away they are, whether they are approaching the room or moving away, etc. What's special about the technology is that it doesn't require any new hardware; all nodes of the system can come from off-the-shelf hardware that most households already possess. This makes our technology both extremely modular and easily integrated into existing systems. Our team was well organized with weekly sprints and check-ins with each other and our supervisor, constant communication and pair programming, as well as occasional personal conversation to ensure best performance from the team. Because we were trying to create something that had never been done before, we used a very systematic approach, first performing many tests and experiments to understand more about the system, then breaking down the problem into smaller portions that we would individually tackle, and then eventually re-combining the pieces using an iterative process. My role on the team for this project mainly involved designing the software algorithms and optimizing them, as well as writing firmware for sensor hardware. I was also involved in sensor fusion and decision making, trying to understand the data we were seeing as well as mapping out where the user is in context to the detection system. We ended with an MVP that interfaced with a Raspberry Pi and created a network of sensors on the user, in rooms, and in the hallways. It determined presence, relative location of the user to a room, and real time movements of the user. Our creation will streamline further development of the full-timers' main presence sensing technology and expand the company's repertoire of presence sensing capabilities. Our work paved the way for Ivani's next projects in the pipeline, People Counting and People Locating.
In addition to the main project, Liani and I also thought up a secondary project that we believed could augment the main project we were working on. I personally spearheaded this exploratory venture, and I ended up creating a sensor construct that integrated additional data streams to improve the output of the main project. The process for this project mirrored that of the main. The augmentation I created stabilized the main algorithm and provided more consistent and accurate outputs. Because of the additional sensors I integrated into the system, we also created the framework for the ability of the technology to learn trends and statistics, thus being able to predict the pathway that a user will most likely take in a home and optimize lighting or other appliances. The construct I added to the original project ended up increasing accuracy of outputs and predictions by about 40%, thus significantly boosting the system's performance.
The technology we were creating was so new that we eventually realized that it could be patented. We contributed to a patent application on this new technology, effectively bolstering company assets. The patent, Reverse-Beacon Indoor Positioning System Using Existing Detection Fields, is currently submitted and is in progress for filing. The company estimates that the patent will be worth at least $300,000 once it's completely filed and being utilized.
Besides the main projects I worked on, I also took initiative to take on several smaller quality of life projects not just for my team but also for the company as a whole. I flushed out a modular code architecture for future software development that increased code readability and organization and also provided easier development of new codebases. The framework compartmentalized the presence sensing process into three main parts, and outlined general methods that all processes should use. The architecture was actually implemented in our team codebase and made both communication and debugging much more efficient. I also laid the foundations for test-driven development by conceptualizing a unit testing system that allowed for more optimized development. I not only designed a robust unit testing process but also wrote a comprehensive guide to allow the full timers to learn about the system on their own time. While the system isn't currently being used because the company is still small enough such that direct communication is faster, the company definitely believes that it will come into use once the company grows further and a more organized system will be needed. Finally, I helped characterize test inputs for system development, running various experiments to help the company better understand the data they were reading. I actually came to several conclusions that gave the full-timers many new things to consider moving forward, such as trends in the data and previously unknown traits that occasionally will be exhibited under certain conditions. Using data analytics, I ended up finding a flaw in the current microcontroller the company was using and confirmed the need to switch to a new microcontroller, which was two times faster and much more consistent.
Overall, the Summer of 2016 has been the most fun, most educational, and most accomplished summer I've ever had. I believe that both Ivani and I have benefitted greatly from this experience, and I can't wait to see what's next, for me and Ivani.
Project: Gemini
Robotics Systems & Integration and Interactive Robotics Laboratory joint venture
Spring 2018
In the Spring of 2018, the highest level course in robotics at Olin, Robotic Systems and Integration, decided to shift its focus towards teaching students professional research and learning first hand how research is conducted in the real world. To make it as realistic as possible and bring in as many resources as we could, the Olin Robotics Laboratory and Robotic Systems and Integration teamed up in a joint venture to launch four research thrusts for a semester. I was the leader of one of those thrusts, in which I combined my existing team from the Interactive Robotics Laboratory (a subset of Olin Robotics) with my class team from Robotic Systems and Integration to form a research group. We set out to research if it was possible to create a robot system that was intelligent enough to build a structure together with a human. By the end of January 2018, we had received over $1000 in research grant funding from the college, and Project Gemini was underway.
I was project manager of my research group, composed of 10 students from both the class and IRL. We set up 4 subteams: Perception, Planning, Controls, and Acutation. Each team worked within themselves to research and complete their portion of the project, and I provided guidance and advice to each team individually, later coordinating efforts to integrate the overall product together as well as leading the high level direction of all subteams so that we all ended up on the same page. I was personally in charge of the Planning team, which was my focus for the first half of the semester. Our job was to figure out how, when given a set of building blocks that constitute the structure in question, should we go about putting them together into a set of instructions for our robot system to build. We performed extensive research of automated building and generalized a set of criteria that constructing structures generally follow. We then decided that based on the way the criteria functioned, an adaptive learning model might be a good idea to be able to adequately cover all criteria named and possibly more. More research led us to reinforcement learning as the learning model of choice.
My team then dived deep into reinforcement learning. To scope properly for a semester, we decided to go with Q-Learning, as it was intuitive yet powerful and easy to set up. Our initial testing with our Q-Learning model only yielded roughly 50% accuracy when given a structure comprised of building blocks. We discovered that processing on all components within the structure was too complex and would require more high-end models that would put us out of scope, therefore we simplified the problem in various ways, for example assuming that each "level" of a structure must be built first before higher levels can be built because of gravity. Through more research and testing, we eventually tuned the reward function and parameters to reach convergence as quickly as possible, which occurred at around 4.5 million trials. We were able to successfully plan instructions for a structure by "levels", and then just concatenated the instructions we received sequentially going up those levels, which achieved the goal of build planning. We attempted to take it further and expand the capability of our Q-Learning model, however we quickly realized that taking on more levels or more components would just take too long for convergence, and advancing the model to something like a DQN learning model would be necessary. However again, due to time, we were unable to meet the stretch goal. Our Q-Learning model that solved structures by "levels" could converge within 3 hours, reach 99.5% accuracy, and performed the desired behavior perfectly within the same order of magnitude in terms of speed as a hard-coded solver. While we could've taken the subteam further with more time, we would still call our achievements a great success. The Planning team proved that it was possible to create an intelligence that was capable of learning how to build a structure once shown its components, and we were able to create an MVP that demonstrated its feasibility.
After my team was nearing their end goal, I began turning towards the other teams and integration. I had been constantly helping other teams and providing advice as project leader the entire semester, but now it was time to begin more actionable items and help all teams converge to the same product. I spent many hours talking with individual teams and facilitating inter-team communications, so that inputs matched outputs and interactions made sense when put together. We ended up a smooth connected interaction that started with a human using toy cubes to create a small model structure and showing it to the robot system, then the system perceiving the structure and recognizing all the components needed to build it, then the planner I was in charge of taking all of the components and figuring out the optimized way to build them all together into a solid structure, then the controller deciding how to actually execute the planned instructions in the real world and then working with the mechanical actuators to physically build the structure using life-sized building blocks. All members worked with me to make sure that their pieces were integrated correctly with subteams they interacted with, and it was a major group effort to combine all of our research efforts into a polished product. By May, we had completed Project Gemini, a dual UR5 robot arm system that could build any structure a human showed it, consisting up to 125 components.
We presented for our final research presentation and Olin Exposition. In both occasions, people were amazed by our results, and we even had visitors make never-before-seen structures to present to Gemini, at which the system recognized, planned, and executed construction of the structures like it was business as usual, creating almost 10 perfect life-sized replicas without any mistakes during live demonstrations. We were incredibly happy with our successes this semester, as this was not only an achievement for the research thrust in the class, but also a big milestone for IRL the research organization. Moving forward, we hope to be able to keep researching in this direction and create more intelligent behaviors that build off of our achievements this semester. We also plan on publishing a research paper later on, with the hopes of attending a robotics conference in the future.
Project: Nevo
Genetic Algorithms Environment
Spring 2017
In the Spring of 2017, for the final project of Computational Robotics, I was tasked with two other Oliners, Shane Kelly and David Zhu, to create something "cool". Given the open-ended project, we wanted to do something learning-based that was outside the "mainstream" bounds of machine learning and neural networks to explore and expand our knowledge. Shane then mentioned that genetic algorithms was a thing, and thus we began Project: Nevo.
Genetic algorithms are as the name suggests, algorithms that take parameters/weights as "genes", and use a process similar to natural selection to evolve the genes to their optimized state. Over many iterations of choosing the "best" genes and mutating them to create potentially even stronger genes, the "most fit" gene can be found, which is then the optimized parameters for a given behavior or objective. We decided to implement a genetic algorithm environment that could teach mobile Neato robots how to perform multi-robot interactions, such as teaching a group of robots to form a line.
David was more into codebase architecture and designing a robust code structure and software flow, so Shane and I were in charge of implementing the core of the genetic algorithm software. David created a base environment that included a modular simulator, and Shane and I worked on the Genetic Algorithm framework. We created a modular system for a generation evolution incubator that could plug and play any "task" given a fitness function and a simulation framework. We then both worked on different tasks, thus completing the environment and creating a polished product. Our approach was to establish a strong core system, and then expand from there with experimentation and iteration. Our core consisted of David's environment wrapped around our evolution system, and we expanded with new tasks while optimizing the existing codebase. Shane and I worked extensively first on making our genetic algorithm work with a simple task, and we performed many tests to find the best parameters for evolution. I then began to work on cooperative tasks, and Shane took on competitive tasks. This involved figuring out how to increase the complexity of the task while ensuring it worked with the evolution system. For cooperative tasks, I had included all Neatos' position and orientations into account and factored them all into the reward functions, with double positives doubling the reward. The simulation framework also had to factor in multiple Neatos, as they had to know each other's positions and orientations. I also took on the task of interfacing between our simulation environment and the real world, using sensor fusion and a mirrored framework to the simulation system to create a new system branch that could easily translate our optimal "genes" to the real world. I used computer vision to map our simulation into a 3D space in the real world, and then replaced simulation portions with apriltag markers and sensors. I also figured out how to apply our software onto multiple robots, thus creating a system of mobile Neatos that could interact with each other. By the end of the semester, we had implemented and optimized Neato systems for Waypoint Navigation, Linear Regression, and Tag.
We presented our work at EXPO, and many were highly impressed with our ability to use a non-mainstream model to exhibit highly organized, intelligent behavior between multiple Neatos. Our professor was especially impressed since we showed him something he had never seen before. This project was a great learning experience and also a chance to better understand robust code structure. I learned a ton about the breadth of learning models out there from Shane, and David taught me that a codebase is never fully optimized, as there are always ways to better streamline software execution or improve code architecture. Moving forward, I want to learn more about the different methods of learning that exist, as well as work with mobile robots even more. There are so many things you can do with Neatos once you bring intelligent behavior onto the table.
Frost
Autonomous Snowball Launcher
Stark Industries
Fall 2016

In October of 2016, I teamed up with friends Cedric Kim, Daniel Daugherty, Kevin Guo, and Jeremy Garcia under the name Stark Industries to design and build an autonomous snowball launcher. With winter coming up in Boston and weather forecasts predicting a bountiful snow season this year, we wanted to collaborate and put our skill sets together to create the ultimate weapon in snowball fights. We noticed from last year's snowball fights that we were really bad at hitting the opposing team, and getting wet in the cold from snow falling into our clothes wasn't fun. We wanted to build a robot that could dominate snowball fights, with bullseye accuracy and strong defense against snow. To make some tangible goals, we set forth a number of specifications that we wanted this robot to have: it would be able to shoot up to 40 feet away, be able to automatically arm and re-arm itself within 6 seconds, find and lock on targets without any user input and fire more accurately than a human, and be able to handle the entire snowball shooting sequence from packing a snowball to firing it by itself. We named this robot Frost.
To build Frost, we decided to split up into subteams to tackle the individual components. Jeremy and I would take on software, and Cedric, Daniel, and Kevin would take on mechanical. Due to a lack of a strong electrical engineer, we decided that we would all pitch in for any electrical portions, of which there were few. We split up the project into four two-week sprints, with goals to meet each sprint. Cedric and I took informal leadership roles in our subteams as well as planning out next steps and sprint goals. Due to schedule conflicts, we decided that each member would be responsible on their own for finishing their portion of that sprint's goal, and as close friends, we trusted each other to do so. With this setup, we managed to complete the project in under 8 weeks.
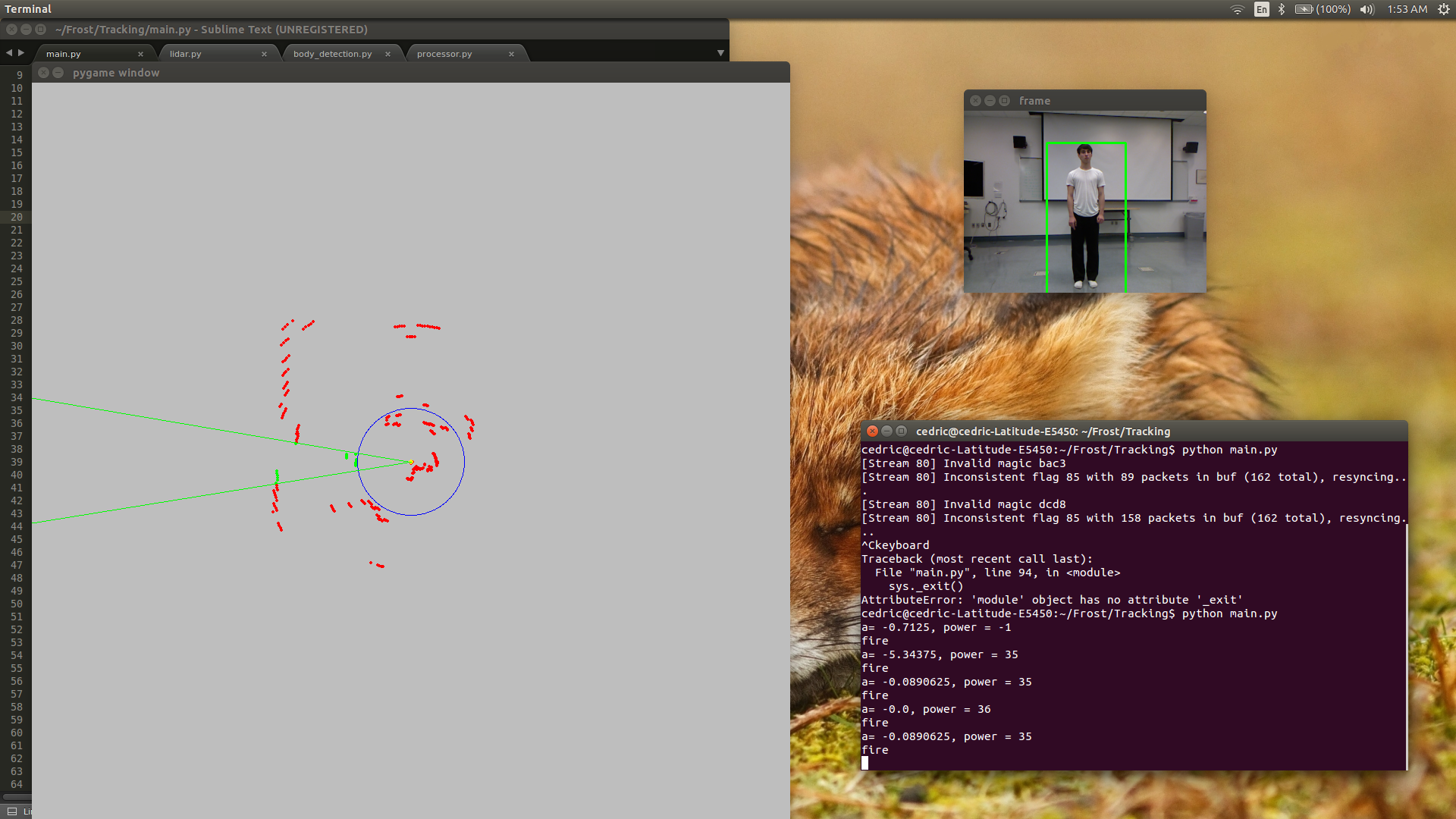
In the First Sprint, we decided to first create a proof of concept that such a robot was physically possible, as there were no online sources to confirm its feasibility. Our goal was to create a prototype, a miniature catapult that could be electronically controlled. On the software team, our main goal for this sprint was to write the firmware for the Arduino that controlled the motors to actuate the catapult and turn the pan control. I worked mainly on getting the firmware logic to work with panning towards a specific direction, arming, firing a set distance, and then re-arming. Jeremy created a basic interface so that we could easily manipulate various variables to test out our catapult prototype. By the end of the sprint, we were able put together a prototype of Frost. I managed to streamline the firing sequence such that we met our goal of arming, firing, and re-arming in under 6 seconds. We tested the catapult in multiple different experiments and confirmed that it was indeed possible to create Frost. It was feasible to create an autonomous snowball launcher. We were on a roll.
For the Second Sprint, our goals became a little too ambitious. We wanted to push our limits and see how far we could get, so we decided to create all the intelligent and autonomous parts of Frost. Mechanical decided to try and build their own LIDAR and create a compactor mechanism for packing snowballs, and software decided to attempt autonomous vision tracking and interface with the LIDAR once built. For this sprint, I worked mainly on interfacing with a Kinect camera and getting computer vision to work with our prototype as well as helping out with interfacing with the LIDAR, and Jeremy worked mainly on experimenting with various methods to try to find and track a human in a camera's field of view. Jeremy found out that motion detection was a viable option, but we soon discovered that the pan motor was too often confused because the outputs weren't consistent enough. The mechanical team also did not have much luck either. At the end of the sprint, neither subteam was able to reach their goals. We decided to pivot away from a completely autonomous robot and tossed the idea of the compactor. Now the robot was autonomous starting from when a user gives it a packed snowball. We treated this sprint as a significant learning experience about proper scoping and understanding our limits.
In the Third Sprint, we kept our same goal as before to finish adding autonomy to Frost, but this time with renewed vigor. I joined Jeremy in experimenting and developing finding and tracking. I discovered a robust method through body detection that used machine learning to search for the contours of a human body, and together Jeremy and I worked on developing this method. We managed to bring accuracy of detecting a human body up to over 90%, and I optimized the algorithm to ensure constant, consistent output so that the actuators would always know where to go. I worked with Cedric on the LIDAR, mainly in creating a multiprocessing code architecture to integrate it with the data from the body detection module. I also wrote out the decision making algorithm that told Frost where to point and how far to shoot based on inputs from the Kinect and the LIDAR. By the end of the third sprint, we had successfully created an intelligent version of Frost, capable of finding targets on its own and firing towards them with a successful hit percentage of about 80%.
In the Fourth and Final Sprint, it was the home stretch, and our goal was to finish building the final robot and integrate all our intelligence on the final version. For the software team, this meant optimizing the LIDAR, body detection, and integration modules and making sure they were perfect. I took on the task of optimizing the software modules, and Jeremy decided to create a nice website to document our work. I managed to stabilize LIDAR output and optimize the body detection module to correctly detect and track bodies almost 100% of the time, with constant output. Finally, I improved the integration and decision making algorithms such that Frost's firing accuracy was about 98%, always shooting within 6 inches of the target's center, which is almost a guaranteed hit. After that, I worked with the team to build the catapult. We finished fabricating and assembling our final catapult, which was bigger, made of metal, and much stronger than the prototype. We also remade our circuit boards and other electrical components to accommodate for the new robot. With the finished Mechanical, Software, and Electrical components ready, we finished our project by integrating all the parts together and improving the final product until it was ready. We completed Frost in December 2016.
Come Olin EXPO, we showcased Frost to the community and let guests have a test run with getting found and shot at by Frost up to 40 feet away. Unfortunately, there was no snow that day, so we settled with a plushy toy. Even then, the crowd was blown away by our work, and many people wanted multiple turns. After some documentation and publicity work, we have completed our work with Frost - the Autonomous Snowball Launcher. Come next semester, when the snow begins to fall, the people who once gaped in amazement will soon run in fear when we return from winter break to dominate the snowball game.
Copyright © thezhangster.com 2021
Made with HTML5, JavaScript, CSS